3 minute(s) à lire
Programmation GPU
Présentation de la programmation GPU avec Nvidia CUDA

(Les illustrations utilisées proviennent du cours de Pierre-François Bonnefoi, source : https://p-fb.net/master1/gpgpu/cours/cuda.pdf)
À propos de la programmation GPU
La programmation GPU (ou GPUGPU pour General-Purpose computing on Graphics Processing Units) vise à exploiter la puissance des calculs qu’est capable une carte graphique, pour des tâches massivement parallélisables.
Tandis qu’un CPU est surtout dédié aux traitements de tâches rapides et séquentielles, les cartes graphiques apportent une nouvelle architecture de programmation très favorable au parallélisme. Le précurseur a surtout été Nvidia qui développe depuis 2007 une interface matérielle et un langage de programmation basé en C : CUDA (Compute Unified Device Architecture)
Cuda ? Comment ça marche ? 🤔
Avec CUDA, on sépare l’architecture CPU (appelé Host) de l’architecture GPU (appelé Device). L’hôte possède sa propre RAM contenant ses programmes et ses variables, tandis que le GPU ne s’occupe de n’exécuter que la partie du code qui lui est dédiée, que l’on appelle kernel. Les deux architectures s’échangent des données via un bus PCI.
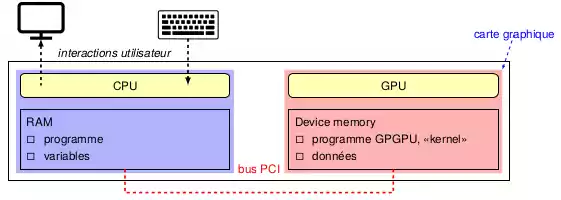
C’est donc toujours le CPU qui aura le contrôle des deux architectures :
- Il alloue de la mémoire sur la carte graphique grâce à l’instruction cudaMalloc
- Le CPU copie les données à transférer vers la RAM de la carte graphique avec l’instruction cudaMemcpy
- Lorsqu’un kernel est appelé, le CPU transmet l’adresse mémoire que le GPU doit exploiter lors de l’exécution de son kernel
- Le CPU récupère alors le résultat obtenu dans le kernel, avant de désallouer la mémoire associée avec l’instruction cudaFree
Et à quoi ça ressemble, un GPU ?
Question pas très évidente, cher ami !
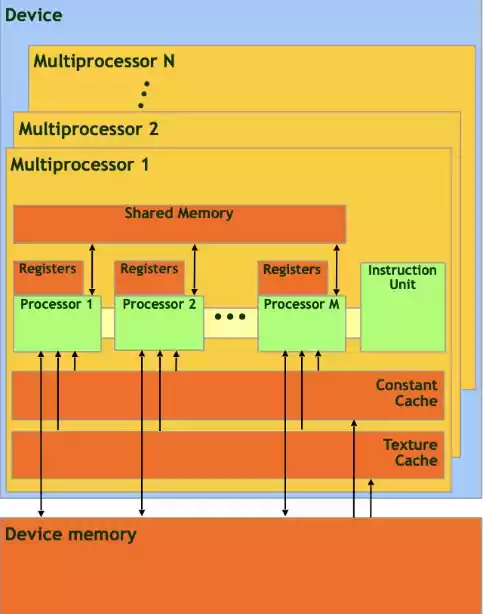
En programmation GPU :
- Ta carte graphique est divisée en plusieurs multiprocesseurs, qui contiennent donc chacun des processeurs
- Tous ces multiprocesseurs partagent une même mémoire globale, en GDDR
- Chaque multiprocesseur partagent une mémoire partagée, sur lesquels les processeurs d’un multiprocesseur peuvent échanger plus rapidement que s’ils passaient par la mémoire globale, mais attention aux accès concurrents !
- Chaque processeur possède ses propres registres, mais de quantité plus petite, de l’ordre de 16 kilooctets
En CUDA, la mémoire est construire similairement, mais de manière hiérarchique :
- Au niveau le plus bas, on trouve la thread, qui possède sa propre mémoire locale
- Vient ensuite les blocs, composé de plusieurs threads exécutées de manière concurrente, et ayant accès à une mémoire partagée
- Au niveau le plus haut, on trouve les grilles, composés de plusieurs blocs de threads, qui utilisent la mémoire globale
Il existe également la notion de warp au sein d’un bloc (un wrap étant un groupe de 32 threads synchronisées), mais si vous souhaitez en savoir plus, je vous invite à suivre le cours de Pierre-François Bonnefoi 😉 : https://p-fb.net/master1/gpgpu/cours/cuda.pdf
Les usages de la programmation GPU
Évidemment, l’usage le plus connu de la programmation GPU reste dans le milieu du jeu-vidéo et des effets spéciaux.
Mais on en trouve aussi dans le milieu scientifique : En fournissant une plus forte puissance de calcul qu’avec un CPU, on peut effectuer des simulations, de l’analyse et du traitement de données en des temps plus raisonnables !
Durant le Master CRYPTIS (et donc en rapport avec la cryptographie RSA), j’ai pu créer des programmes CUDA permettant de casser la factorisation en nombre premiers de nombres immenses. 😉
